Offline e Storage em HTML5
Não existe nada tão desagrada?vel para um usuário do que uma brusca queda de conexa?o na navegação, especialmente durante o preenchimento de um grande formula?rio de dados. A necessidade de recomeçar o procedimento pode levar até mesmo ao não retorno do internauta à aplicação. Além disso, existem procedimentos, como a leitura de pa?ginas institucionais, por exemplo, que sequer necessitariam de uma conexa?o permanente.
Para tais situações, o W3C trouxe uma solução simples, pore?m, eficiente: o tratamento off-line para o site. Isso significa que, caso a conexa?o caia durante o uso da aplicação, tomados os devidos cuidados, ela na?o vai parar de funcionar – desde que, é claro, não sejam necessárias informações adicionais.
O tratamento off-line é configurado em um arquivo de manifesto — que na?o e? nada mais e? do que uma lista de arquivos necessa?rios para que a aplicação funcione sem conexa?o. Assim, os arquivos sa?o automaticamente copiados em cache pelo navegador, com a finalidade de mantê-la funcionando.
O manifesto também pode conter uma relação dos arquivos na?o necessa?rios para uso offline (que não sera?o armazenados localmente) e uma listagem de arquivos alternativos para uso offline – devidamente preparados para este fim –, que tomarão o lugar de outros quando a conexão cair. Observe o exemplo de arquivo de manifesto:
01 CACHE MANIFEST
02
03 CACHE:
04 images/favicon.ico
05 images/logo.png
06 index.html
07 css/stylesheet.css
08 js/script.js
09
10 NETWORK:
11 login.php
12 /application
13
14 FALLBACK:
15 /index.php /index_offline.html
16 *.php /offline.html
Na seção CACHE serão relacionados todos os arquivos a serem copiados pelo navegador para que estejam disponi?veis durante a queda de conexa?o. Repare que se deve ater a arquivos como .html, .js, .css e imagens como .png, .jpg e .gif, que sa?o passi?veis de rodar no cliente (o chamado run at client). Arquivos que necessitem de interpretador do lado servidor (como .php, .aspx, .jsp) precisarão ser substituídos no fallback.
Na seça?o NETWORK, relacione os arquivos na?o necessa?rios para uso offline. Em FALLBACK, relacionam-se quais arquivos serão substituídos por outros (em ordem sequencial, separados por espaço).
Armazenar informações de aplicações é uma necessidade recorrente que os bancos de dados, com seus excelentes mecanismos de persistência, cumprem de forma rápida e segura. Entretanto, nem sempre o banco de dados se faz necessário, pois algumas informaço?es dizem respeito a utilização da aplicação naquele momento – o que é útil para a interface do usua?rio, mas resulta em um tra?fego de rede desnecessa?rio.
Neste caso, guardamos as informações no lado cliente e, por de?cadas, a u?nica forma de se fazer isso era o cookie. Infelizmente, este recurso se tornou cada vez mais obsoleto, pois guarda um volume de informações muito pequeno (até 4 KBytes) e de uma forma muito insegura. Para resolver o problema, os desenvolvedores do HTML5 criaram duas novas possibilidades para armazenamentos em navegadores. A primeira é o Banco de Dados do lado cliente, antigamente representado pelo Web SQL Database, descontinuado e agora substitui?do pelo IndexedDB. O banco de dados IndexedDB permite o armazenamento e manipulação de um grande volume de informações usando linguagem SQL ou outras técnicas, e, por esta razão, é considerado um banco noSQL (not only SQL).
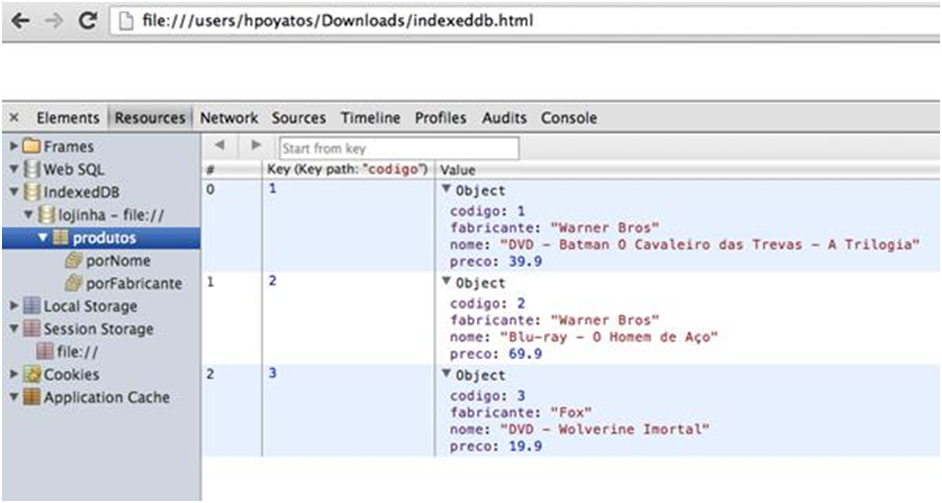
O exemplo de armazenamento utilizando IndexedDB abaixo cria um repositório de produtos, populando a tabela com três deles:
01 <html>
02 <head>
03 <meta charset=”utf-8″>
04 <title>Exemplo IndexedDB</title>
05 </head>
06 <body>
07 </body>
08 </html>
09 <script type=”text/javascript”>
10 var request = indexedDB.open(“lojinha”);
11 request.onupgradeneeded = function()
12 {
13 // Se o banco de dados não existir ainda, cria objetos de armazenamento
14 var db = request.result;
15 var store = db.createObjectStore(“produtos”, {keyPath: “codigo”});
16 var nomeIdx = store.createIndex(“porNome”, “titulo”, {unique: true});
17 var fabricanteIdx = store.createIndex(“porFabricante”, “fabricante”);
18 // Populando o banco com alguns produtos
19 store.put({codigo: 1,
20 nome: “DVD – Batman O Cavaleiro das Trevas – A Trilogia”,
21 fabricante: “Warner Bros”,
22 preco: 39.90});
23 store.put({codigo: 2,
24 nome: “Blu-ray – O Homem de Aço”,
25 fabricante: “Warner Bros”,
26 preco: 69.90});
27 store.put({codigo: 3,
28 nome: “DVD – Wolverine Imortal”,
29 fabricante: “Fox”,
30 preco: 19.90});
31
32 };
33 request.onsuccess = function() {
34 db = request.result;
35 };
36 </script>
Teremos como resultado a tela abaixo:
A outra possibilidade de armazenamento local são os chamados sessionStorage e localStorage, recursos mais simples que o IndexedDB, mas mais robustos do que os antigos cookies. O funcionamento de ambos é similar, sendo a única diferença o armazenando utilizando sessionStorage, que compartilha as informações do website todo, mesmo abrindo várias abas (diferentemente do localStorage, cujas informações ficam restritas à apenas a aba em funcionamento).
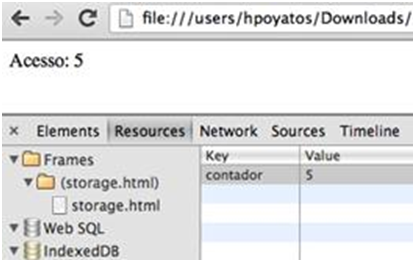
Abaixo é exposto um exemplo de armazenamento usando SessionStorage em funcionamento:
01 <html>
02 <head>
03 <meta charset=”utf-8″>
04 <title>Exemplo de Armazenagem</title>
05 </head>
06 <body>
07 <div id=”contador”></div>
08 </body>
09 </html>
10 <script type=”text/javascript”>
11 // Verifica se existe suporte ao SessionStorage
12 if(sessionStorage)
13 {
14 if(!sessionStorage.contador) sessionStorage.contador = 0;
15 sessionStorage.contador++;
16 document.getElementById(‘contador’).innerHTML = ‘Acesso:
17 ‘+sessionStorage.contador;
18 }
19 </script>
Como resultado, temos a representação abaixo:
Henrique Poyatos é coordenador pedagógico de EAD e professor dos cursos de graduação e MBA da FIAP. Pós-graduado em Gerenciamento de Projetos e tecnólogo em Processamento de Dados (FIAP). Atua no mercado de desenvolvimento para Internet desde 1996 e coordenou projetos de tecnologia para empresas como Caixa Econômica Federal, Nossa Caixa, McDonalds, Metrô de São Paulo e clientes internacionais.